
I) Chapters 1 – 4 of this introduction to Bayesian inference and model selection. Although the intended applications are in cosmology, the first four chapters are a general introduction to the subject and require no specialized knowledge.
II) For a no nonsense introduction to differential geometry at the necessary level, please refer to Chapter 1 of Methods of Information Geometry (available via Leiden Library digital proxy). N.B. This book can also be viewed as a comprehensive reference on information geometry, and we’ll refer to it again in the future.
III) Chapter 2, section 2.3 of Methods of Information Geometry, and Chapter 1, section 1.6 if you need a review of general affine connections in differential geometries.
Advanced reading
I) Chapter 2, section 2.5 of the same reference.
II) There is strong evidence that the three neutrino species in our universe have small, non-vanishing masses. The precise hierarchy of these masses however, is something we’re still trying to measure. Whether various data sets favor one type of hierarchy over another strongly depends on the priors one assigns, highlighting an irreducible feature of Bayesian reasoning — your inference is only as good as your priors. This paper attempts to understand precisely how these conclusions can depend on the choice of priors, and is an excellent demonstration of what is potentially at stake when applying Bayesian reasoning to the outcome of experiments and observations. N.B. This paper should be understandable without needing much specialized knowledge about particle physics or astrophysical and cosmological data sets — it’s primarily a data analysis methodology paper.
Entertainment and culture I: Reconstructing a dead language
The Indus Valley Civilization (IVC) was an ancient urban civilization (~3,300 BCE to 1,300 BCE) whose peak was roughly contemporaneous to ancient Egypt and Mesopotamia, although probably had its beginnings much earlier. Unlike ancient Egypt and Mesopotamia, the IVC’s existence was forgotten to the wider world (for idiosyncrasies specific to the Indian subcontinent) until British colonial officials rediscovered it through a large number of artifacts and clay tablets, unearthed while constructing railways in the Indus valley region of what is modern day Pakistan. What they subsequently went on to uncover was a vast civilization that was highly urbanized in nature with extensive trade connections with Mesopotamia and beyond. However, aside from physical artifacts, very little is known of the IVC. This is primarily because the writing system remains undeciphered. In fact, given that the majority of inscriptions were found in the form of seals no more than five characters long, it was unclear whether it corresponded to writing system at all, as opposed to being non-linguistic symbols with other significance, as has turned out to be the case for other examples of bronze age inscriptions. The absence of any bilingual inscriptions (like the Rosetta stone), or inscriptions of large lengths, has hindered attempts to understand this script.
However, just because traditional methods of deciphering ancient languages can’t be applied here, doesn’t mean that we should give up. In fact, statistical sampling of example inscriptions can be done, from which conditional probabilities for particular sequences of symbols can be constructed, and the conditional entropy can be inferred from inscriptions of varying lengths, and compared to the expected result for known linguistic writing systems:
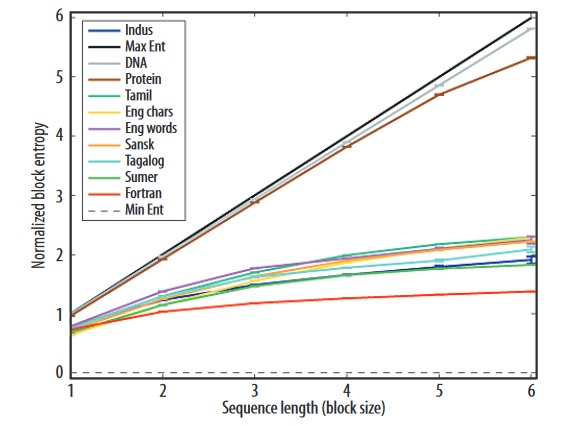
The limiting black solid line at the top is for a completely random sequence, and the dashed line at the bottom is for a sequence that is a single repeated symbol. Clearly, the IVC script appears to carry the conditional information entropy expected of a linguistic script. You can read the details of the study from which the figure was drawn in this short paper. Moreover, some scientists posit that with more and more writing samples being uncovered as the years go on, that perhaps a Markov Chain modelling of the samples can help reconstruct damaged samples, and could even help us reconstruct a grammar for this dead language, helping to bring it back to life.
If you’re interested, here’s one of the authors of the studies above (a computational neuroscientist by day) giving a TED talk on the topic:
https://embed.ted.com/talks/lang/en/rajesh_rao_a_rosetta_stone_for_a_lost_language
Entertainment and culture II: biased estimators during the pandemic
A statistic of great importance during an epidemic is the case fatality ratio (CFR). This is the number of cases that are detected that result in fatalities. Were one to try and estimate this using the naïve estimator of simply taking the number of cumulative deaths attributed to the disease in question D(t), and divide this by the cumulative number of cases C(t), so that
CFR(t) = D(t)/C(t) [simple estimate 1]
one would expect this to converge on the true CFR given sufficiently long. Indeed this is certainly true towards the end of the epidemic once all the data is in, however at the beginning and the middle of it, the CFR as estimated in this manner turns out to be significantly biased. This means the majority of figures you may have been hearing over the past year in reference to the CFR of Covid may not be as accurate as they purport to be given that we don’t know at what stage of the epidemic we’re in. It turns out that a more accurate estimator for the CFR in the early and mid stages of an epidemic is given by
CFR(t) = D(t)/(D(t) + R(t)) [simple estimate 2]
where R(t) is the cumulative number of recoveries up till the time t. There are of course, more sophisticated estimators available, but even this simple estimator turns out to be a big improvement, as depicted in the plot below for data acquired during the short lived SARS-Cov-1 epidemic that rocked Hong Kong SAR, China, and to a lesser extent, Canada in 2003:
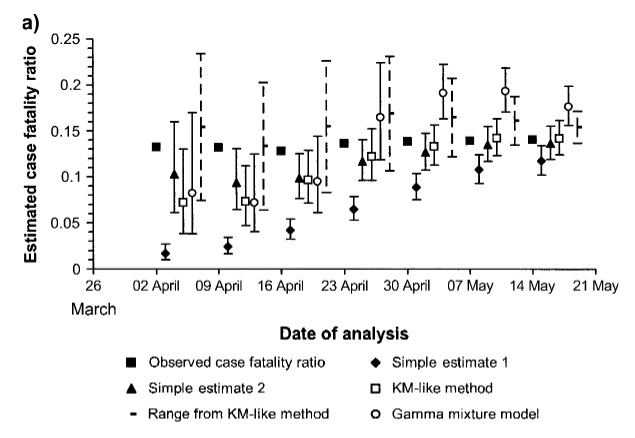
A more detailed discussion of this, and the more accurate estimators also plotted above are given in this paper.
